
I terremoti hanno la caratteristica di concentrarsi nel tempo e nello spazio. Vale a dire che se è appena avvenuto un terremoto, è più probabile che nella zona circostante ne avvengano altri, per un periodo di tempo che può estendersi anche per anni.
Un esempio è la sequenza che colpì il Centro Italia tra il 2016 e il 2017, a cui sono attribuite 299 vittime. Iniziò il 26 agosto 2016 con una scossa di magnitudo 6 con epicentro al confine tra le province di Rieti e Ascoli Piceno e che distrusse quasi del tutto la parte antica di Amatrice. Proseguì con tre scosse nel mese di ottobre con magnitudo tra 5,5 e 6,5 nei territori della provincia di Macerata e di Perugia. Si concluse il 18 gennaio 2017 nella zona di Campotosto, provincia dell’Aquila al confine con la provincia di Rieti.
Un altro esempio famoso è la sequenza di Canterbury, che colpì la Nuova Zelanda tra il 2010 e il 2016, facendo registrare uno dei due terremoti più letali nella storia del paese, quello che interessò la città d Christchurch il 22 febbraio del 2011 uccidendo 185 persone. Il governo neozelandese istituì una commissione di inchiesta sulla sequenza per indagare sui cedimenti degli edifici e fornire raccomandazioni. La commissione cercò anche di capire se sarebbe stato possibile “prevedere” la scossa del 22 febbraio, allertare la popolazione e salvare delle vite.
Questa caratteristica di “affollamento” nel tempo e nello spazio, che viene chiamata clustering, può essere infatti sfruttata per formulare previsioni probabilistiche nel breve e medio termine, utili ad aiutare le comunità a prepararsi a terremoti potenzialmente devastanti.
In uno studio recente, pubblicato sulla rivista Seismological Research Letters, due sismologi dell’Università di Napoli Federico II hanno proposto un modello semplificato per descrivere il clustering sismico. Il modello permetterebbe di sfruttare i dati raccolti in zone del mondo dotate di reti sismiche capillari per migliorare le previsioni probabilistiche in zone meno monitorate ma con un rischio sismico elevato.
Ispirati dal contagio
L’idea alla base del modello è nata nel 2019. «Avevamo studiato le sequenze associate ai terremoti di magnitudo sei in Giappone, California e Italia, e ci eravamo resi conto che avevano le stesse caratteristiche in termini di correlazioni spaziali e temporali», spiega Warner Marzocchi che ha coordinato lo studio. «Così abbiamo pensato che la descrizione statistica del clustering fosse in qualche modo universale.»
Per testare questa ipotesi, Marzocchi insieme a Simone Mancini, primo autore dello studio, hanno scelto un modello ispirato alla dinamica di diffusione delle epidemie, chiamato Epidemic Type AfterShock (ETAS). In questo modello, ogni nuova persona infetta può dare luogo a una catena di contagio e ciascuna persona in questa catena può avviare a sua volta un’altra catena di trasmissione dell’infezione. Allo stesso modo, ogni scossa può dare origine a una serie di nuove scosse con una probabilità che decresce esponenzialmente allontanandosi dall’epicentro e man mano che il tempo passa. In effetti processi di questo tipo, chiamati self-exciting point-processes, si trovano un po’ dappertutto. Sono tali i guasti di un computer, le chiamate in pronto soccorso, gli incidenti stradali o la microstruttura delle compravendite finanziarie.
I modelli della famiglia ETAS, usati anche nel sistema italiano di operational earthquake forecasting di cui avevamo parlato qui, hanno anche un’altra componente, chiamata di background. Alcuni terremoti, infatti, non vengono innescati da scosse precedenti ma sono causati dalle forze tettoniche. È simile alla distinzione che si fa in una catena di trasmissione epidemica tra “paziente zero” e i casi successivi di infezione.
Universalità vuol dire semplicità
Marzocchi e Mancini hanno fissato la componente del modello che descrive il clustering quasi del tutto sulla base dei risultati ottenuti da altri studi, tra loro convergenti. Questo passaggio è molto importante perché la stima dei numerosi parametri che descrivono il meccanismo del clustering può essere molto difficile e introdurre incertezze significative soprattutto in aree in cui non si ha a disposizione un numero sufficiente di sequenze sismiche di buona qualità da cui “imparare”.
«Invece, la sismicità di background è specifica di ogni area geografica e dell’orizzonte temporale che consideriamo», spiega Marzocchi. Si tratta del tasso di sismicità di un territorio, cioè del numero medio di terremoti che ci aspettiamo avvengano in un certo intervallo di tempo in quel territorio. «Qui il motore è fondamentalmente la tettonica. Giappone e California hanno tassi di sismicità più alti dell’Italia perché le placche si muovono più velocemente», spiega Marzocchi.
Per fissare il tasso di sismicità Marzocchi e Mancini hanno considerato il catalogo HORUS, un catalogo di terremoti italiani avvenuti tra il 1971 e il 2021 registrati strumentalmente. «Si tratta di un catalogo completo sopra magnitudo 3,95», spiega Marzocchi, «cioè di un catalogo in cui siamo ragionevolmente sicuri di non aver perso molti eventi sismici sopra quella magnitudo.» Ottengono un tasso di sismicità per l’Italia pari a circa 18 terremoti sopra magnitudo 3,95 all’anno.
Tuttavia, questi 18 terremoti non sono distribuiti uniformemente sulla penisola. Per descrivere questa variabilità spaziale, Marzocchi e Mancini hanno fatto ricorso al modello di pericolosità sismica per l’Italia nella sua versione più recente, chiamato MPS19 (che però non è stato mai approvato dalla Protezione Civile per cui a livello normativo vale ancora quello formulato nel 2004).
Il modello di pericolosità per l’Italia stima i tassi di sismicità con una risoluzione di circa quattro chilometri quadrati sul territorio della penisola. Per farlo considera la posizione e le caratteristiche delle faglie, insieme all’intera storia sismica italiana, raccolta nel Catalogo Parametrico dei Terremoti Italiani (CPTI) che comprende i terremoti dall’anno 1000 al 2020. Questo è fondamentale perché i terremoti forti sono eventi rari e senza serie storiche sufficientemente lunghe si perderebbero sequenze molto importanti. «Se ci limitassimo agli ultimi cinquant’anni perderemmo, per esempio, la sequenza del 1968 in Belice», commenta Marzocchi.
E la magnitudo?
Fin qui non abbiamo parlato di magnitudo, cioè di quanta energia hanno i terremoti del background e quelli innescati. Per entrambi vale una legge universale che descrive in che proporzione avvengono terremoti con diverse magnitudo. Sostanzialmente questa legge ci dice che il numero di terremoti decresce esponenzialmente con la magnitudo (si chiama legge di Gutenberg-Richter).
Marzocchi suggerisce di pensare ai terremoti come biglie colorate in un’urna da cui possiamo pescare a caso. «Se nell’urna ci sono 1000 biglie bianche, che rappresentano i terremoti di magnitudo 3, ce ne saranno circa 100 verdi per i magnitudo 4, 10 gialle per i magnitudo 5 e una rossa per i magnitudo 6», spiega. La composizione dell’urna è, per questi livelli di magnitudo, uguale dappertutto.
Ogni volta che c’è un terremoto, la probabilità che questo abbia magnitudo sei è uguale alla probabilità di pescare una biglia rossa dall’urna e questa è uguale in California come in Italia. Ciò che cambia passando da un’area geografica all’altra è quante volte possiamo pescare dall’urna, cioè quanti terremoti avvengono in un certo intervallo di tempo. Questo si traduce in un amento della probabilità complessiva di avere un terremoto di magnitudo sei. «Se peschiamo una sola volta, la probabilità di estrarre la biglia rossa è molto bassa dappertutto. Ma se possiamo pescare molte volte, la probabilità di ottenere almeno una biglia rossa aumenta», spiega Marzocchi.
Previsione di breve termine: operational earthquake forecasting
Per prima cosa, Marzocchi e Mancini hanno valutato il loro modello, denominato SimplETAS, nel breve termine, considerando la sequenza che ha colpito il Centro Italia tra il 2016 e il 2017.
A questo scopo hanno fissato i tassi di sismicità i dati del catalogo HORUS fino al 23 agosto 2016, il giorno prima della scossa che distrusse il centro storico di Amatrice. A questo punto hanno usato il modello SimplETAS, per simulare una serie di sequenze sismiche per le 24 ore successive, cioè per la giornata del 24 agosto 2016. Hanno confrontato le sequenze simulate con quella osservata e hanno valutato l’attendibilità probabilistica delle loro previsioni. A quel punto hanno usato lo stesso modello SimplETAS ottenuto con i dati fino al 23 agosto 2016 per simulare che i terremoti osservati il 24 agosto avrebbero innescato il 25 agosto, per poi confrontarli con quelli osservati. Questa procedura è la stessa utilizzata dal sistema di previsione operativa italiano.
Hanno eseguito il confronto giornaliero per un anno e lo hanno valutato utilizzando le metriche sviluppate dal Collaboratory for the Study of Earthquake Predictability (CSEP), un collettivo di ricercatori dedicato alla valutazione delle previsioni sismiche di cui abbiamo raccontato qui. Gli autori concludono che nel complesso «SimplETAS riproduce fedelmente i tassi giornalieri di attività sismica di magnitudo superiore a 3,95 osservati durante la sequenza considerata.» Il modello verrà ora valutato insieme ad altri nell’ambito del nuovo esperimento organizzato da CSEP per l’Italia.
Previsioni di medio e lungo termine
Marzocchi e Mancini hanno poi testato la validità del loro modello nel medio e lungo termine. Hanno fissato i parametri del modello come abbiamo spiegato prima, usando i cinquant’anni del catalogo HORUS e la mappa di pericolosità sismica per ottenere i tassi di sismicità su tutto il territorio della penisola. Hanno poi generato diecimila cataloghi sintetici per i 50 anni dal 1972 al 2021 e per i 392 anni dal 1630 al 2021 e li hanno confrontati con i terremoti realmente osservati in quei due periodi secondo il Catalogo Parametrico dei Terremoti Italiani. Il confronto è basato sul numero totale di terremoti previsti in sette aree in cui è suddiviso il territorio italiano.
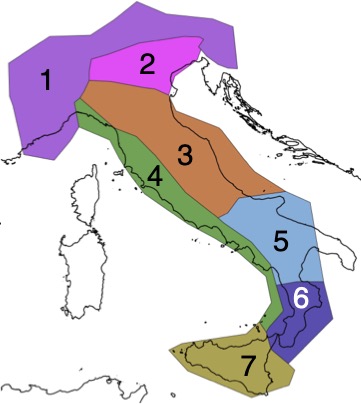
Mappa delle aree su cui viene valutato il modello SimplETAS. Il modello viene usato per simulare I terremoti e costruire dei cataloghi sismici sintetici. Per ogni area vengono contati i terremoti osservati realmente e raccolti nel Catalogo Parametrico dei Terremoti Italiani (CPTI) e confrontati con il numero di scosse contenute nei cataloghi sintetici. L’immagine è presa da Visini, F. et al., “Earthquake Rupture Forecasts for the MPS19 Seismic Hazard Model of Italy. Ann. Geophys. 2021, 64 (2), SE220 DOI:10.4401/ag-8608 (CC BY-NC).
Il confronto va a buon fine quando dei diecimila cataloghi simulati non più del 5% hanno un numero totale di terremoti inferiore o superiore a quello osservato. «Questo vuol dire che ho il 5% di probabilità di sbagliare accettando l’ipotesi che il modello SimplETAS descriva bene i dati», spiega Marzocchi.
Nel periodo 1972-2021, la percentuale di cataloghi simulati che ha un numero totale di terremoti inferiore o superiore a quello osservato è meno del 5% per tutte le aree tranne una, quella che comprende l’arco alpino (area 1 nella figura sopra). Per l’arco alpino, i cataloghi simulati tendono a sovrastimare il numero di terremoti. «I risultati sono nel complesso soddisfacenti», commenta Marzocchi, «il risultato negativo nell’arco alpino non mi sorprende, l’area comprende un territorio molto eterogeneo dal punto di vista sismico, che va dal Friuli alla Liguria.»
La validità dell’approccio SimplETAS nel medio termine è stata confermata anche da uno studio del 2025, che si è concentrato su altre due regioni crostali, la Turchia e la Croazia.
Gli autori hanno utilizzato per la parte di clustering i parametri ottenuti dal catalogo dei terremoti dell’Italia centrale, che è lungo, di buona qualità e contiene molte sequenze sismiche. Solo per la sismicità di background hanno sfruttato i dati specifici delle due regioni considerate. Hanno così simulato dei cataloghi sismici lunghi 30 anni per la Croazia e 20 anni per la Turchia (1992-2021 per la Croazia e 2002-2023 per la Turchia) che si sono rivelati in buon accordo con quelli osservati. Questo indica che modelli di tipo epidemico definiti sulla base di regioni con dati di alta qualità possono essere sfruttati per regioni che invece hanno cataloghi incompleti o in cui mancano sequenze sismiche significative. «I nostri risultati sembrano indicare che la produttività delle sequenze sismiche per eventi crostali non dipenda dal contesto geografico», commenta Paolo Bazzurro, ingegnere sismico della Scuola Universitaria Superiore IUSS di Pavia e coordinatore dello studio su Croazia e Turchia.
Tornando in Italia, il confronto sul lungo termine, ovvero per il periodo 1630-2021, ha mostrato che la percentuale di cataloghi simulati che ha un numero totale di terremoti inferiore o superiore a quello osservato è inferiore al 5% per tutte le aree tranne una, quella dell’arco calabro (regione 6). Sull’arco calabro, i cataloghi simulati tendono a sottostimare il numero di terremoti.
Marzocchi spiega che questo potrebbe essere dovuto al fatto che «la mappa di pericolosità che usiamo per descrivere la variabilità spaziale della sismicità non tiene conto dei terremoti dovuti alla tettonica di subduzione, ma solo a quella crostale.»
Considerare le sequenze per le stime di rischio
I risultati positivi ottenuti nel lungo termine suggeriscono che questo modello potrebbe essere utile anche per la mitigazione del rischio sismico.
Uno dei modi per ridurre la probabilità che un terremoto causi danni a strutture, infrastrutture, e di conseguenza alle persone, è costruirle in modo che resistano alle scosse più forti che è ragionevole aspettarsi nel loro arco di vita. Le norme per le costruzioni in Italia impongono che le strutture vengano progettate per resistere ad accelerazioni del suolo che hanno una probabilità del 10% di essere superate in 50 anni. Queste accelerazioni sono calcolate con il modello di pericolosità che abbiamo citato prima e vengono riassunte in una mappa di pericolosità.
«La mappa di pericolosità sismica è basata su un catalogo declusterizzato, cioè un catalogo in cui vengono tenute solo le scosse principali, quelle con magnitudo maggiore, ma questo può causare una sottostima dei tassi di sismicità», spiega Marzocchi. «Con Matteo Taroni nel 2014 abbiamo messo a punto una correzione dei tassi di sismicità che tenga conto dei terremoti innescati, e quel metodo è oggi usato nelle mappe di Stati Uniti e in Nuova Zelanda. Tuttavia, penso che usare il modello SimplETAS per generare dei cataloghi sintetici che comprendano sequenze sismiche complete sia una procedura statisticamente più robusta.»
Bazzurro sottolinea che avere sequenze sismiche complete di tutte le scosse e non solo di quelle principali è ancora più importante per quantificare l’impatto sugli edifici.
L’idea che si possano considerare solo le scosse principali è basata sull’assunzione che se un edificio è in grado di resistere alla scossa con la magnitudo più alta in una sequenza, resiste anche alle scosse di magnitudo inferiore che precedono o seguono la scossa principale. Quest’assunzione si è rivelata troppo semplicistica per due motivi.
Primo: non è detto che i terremoti di magnitudo maggiore generino gli scuotimenti del suolo più intensi, potrebbero attivarsi segmenti diversi una faglia e generare terremoti più superficiali e dunque più distruttivi a parità di magnitudo. Secondo: un edificio danneggiato da una scossa può essere più vulnerabile alla successiva. «La prima scossa trova l’edificio senza danno, le seguenti scosse seguenti possono continuare a far progredire il danno in una struttura già indebolita», commenta Bazzurro. Aggiunge che è importante anche conservare la struttura temporale delle sequenze sismiche: «per valutare il danno cumulato fa molta differenza se tra un evento e l’altro passa un mese o vent’anni.»






